目录
基本概念
二叉搜索树的实现
插入结点
查找结点
删除结点
删除结点左为空
删除结点右为空
基于特殊情况的优化
删除结点左右不为空
基于特殊情况的优化
完整代码
二叉搜索树的实际应用
K和KV模型
改造二叉搜索树为为KV模型
基本概念
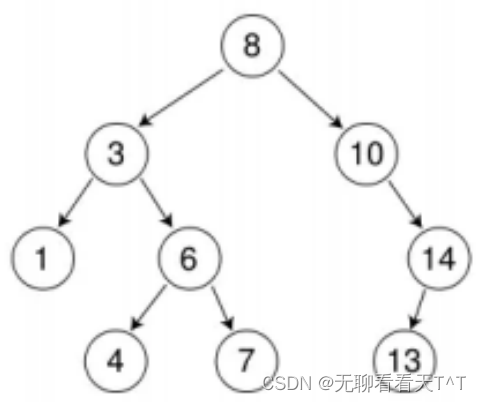
1、二叉搜索树又称二叉排序树
2、左子树上的所有值均小于根节点,右子树上的所有值均大于根节点
3、一个结点的左右子树均为二叉搜索树
二叉搜索树的实现
插入结点
bool Insert(const T& key)
{
//头结点为空就造一个头结点
if (root == nullptr)
{
root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = root;
//遍历寻找
while (cur)
{
if (cur->key< key)//当前结点的值小于插入结点的值,就进入右子树判断
{
parent = cur;//走之前保留之前的信息,便于找到时向前一个结点尾插
cur = cur->right;
}
else if (cur->key> key)//当前结点的值大于插入结点的值,就进入左子树判断
{
parent = cur;
cur = cur->left;
}
else//相同时
{
return false;
}
}
//插入新节点
cur = new Node(key);
if (parent->key< key)
{
parent->right = cur;
}
else
{
parent->left = cur;
}
return true;//成功插入返回true
}查找结点
bool Find(const T& key)
{
Node* cur = root;//从头结点开始查找
while (cur)
{
if (cur->key< key)
{
cur = cur->right;
}
else if (cur->key> key)
{
cur = cur->left;
}
else
{
return true;//遍历找到了cur->key== key就返回true
}
}
return false;//没找到就返回false
}删除结点
删除结点左为空

//删除结点的左节点为空
if (cur->left == nullptr)
{
if(cur == parent->left)
{
parent->left = cur->right;
}
else
{
parent->right = cur->left;
}
delete cur;
}删除结点右为空
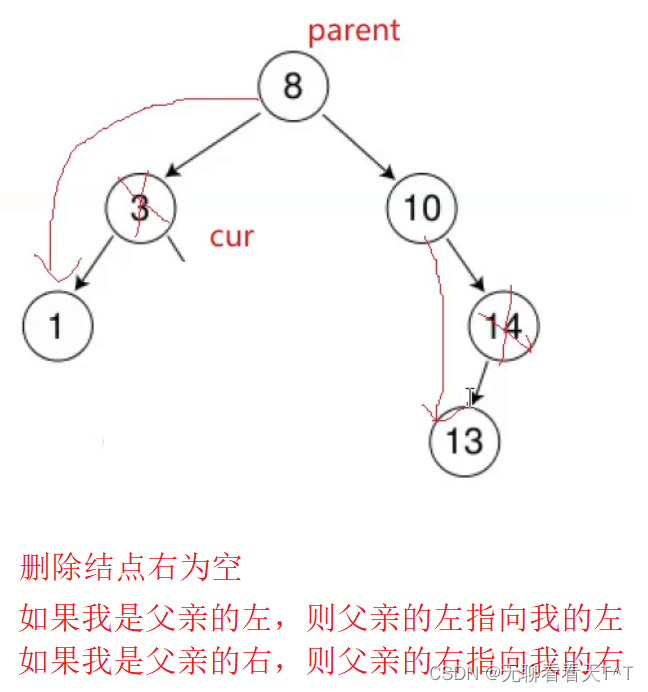
//删除结点的右节点为空
else if (cur->right == nullptr)
{
if (cur == parent->left)
{
parent->left = cur->left;
}
else
{
parent->right = cur->left;
}
delete cur;
}基于特殊情况的优化

//删除结点的左节点为空
if (cur->left == nullptr)
{
//删除结点是根节点
if (cur == root)
{
root = cur->right;
}
else
{
if(cur == parent->left)
{
parent->left = cur->right;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
//删除结点的右节点为空
else if (cur->right == nullptr)
{
//删除结点是根节点
if (cur == root)
{
root = cur->left;
}
else
{
if (cur == parent->left)
{
parent->left = cur->left;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
删除结点左右不为空

图画反了
//删除结点的左右结点均不为空
else
{
//查找右子树的最左结点替代删除
Node* rightMinParent = null;//记录交换结点的父亲结点
Node* rightMin = cur->right;//记录交换节点
//遍历寻找删除结点的右子树的最左结点
while (rightMin->left)
{
rightMinParent = rightMin;
rightMin = rightMin->left;
}
swap(cur->key, rightMin->key);
rightMinParent->left = rightMin->right;//防止交换结点点还有右子树(交换结点不可能有左子树,
//因为交换结点就是删除结点的右子树的最左结点,如果它还有左子树那么最左结点就不是它)
delete rightMin;//rightMin负责找到交换结点,找到并交换后它没用了可以直接删除
}基于特殊情况的优化

//删除结点的左右结点均不为空
else
{
//查找右子树的最左结点替代删除
Node* rightMinParent = cur;//如果要删除的是根节点,(即使不删除根节点,一旦进入循环则parent也会直接发生变化)
Node* rightMin = cur->right;//记录交换节点
//遍历寻找
while (rightMin->left)
{
rightMinParent = rightMin;
rightMin = rightMin->left;
}
swap(cur->value, rightMin->key);
//rightMin是parent的左,就令parent的左指向rightMin的右
if (rightMinParent->left == rightMin)//不删除根节点时都会满足该条件
rightMinParent->left = rightMin->right;
//rightMin是parent的右,就令parent的左指向rightMin的右
else
rightMinParent->right = rightMin->right;//处理删除根节点的特殊情况
delete rightMin;
}完整代码
#pragma once
#include <iostream>
using namespace std;
template<class T>
struct BSTreeNode
{
BSTreeNode<T>* left;
BSTreeNode<T>* right;
T value;
BSTreeNode(const T& key)
:left(nullptr)
,right(nullptr)
,value(key)
{}
};
template<class T>
class BSTree
{
typedef BSTreeNode<T> Node;
public:
bool Insert(const T& key)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = root;
//遍历寻找
while (cur)
{
if (cur->key< key)//当前结点的值小于插入结点的值,就进入右子树判断
{
parent = cur;//走之前保留之前的信息,便于找到时向前一个结点尾插
cur = cur->right;
}
else if (cur->key> key)//当前结点的值大于插入结点的值,就进入左子树判断
{
parent = cur;
cur = cur->left;
}
else//相同时
{
return false;
}
}
//插入新节点
cur = new Node(key);
if (parent->key< key)
{
parent->right = cur;
}
else
{
parent->left = cur;
}
return true;//成功插入返回true
}
bool Find(const T& key)
{
Node* cur = root;
while (cur)
{
if (cur->key< key)
{
cur = cur->right;
}
else if (cur->key > key)
{
cur = cur->left;
}
else
{
return true;
}
}
return false;
}
bool erase(const T& key)
{
Node* parent = nullptr;
Node* cur = root;
while (cur)
{
if (cur->key< key)
{
cur = cur->right;
}
else if (cur->key> key)
{
cur = cur->left;
}
//遍历寻找到要删除的值
else
{
//删除结点的左节点为空
if (cur->left == nullptr)
{
//删除结点是根节点
if (cur == root)
{
root = cur->right;
}
else
{
if(cur == parent->left)
{
parent->left = cur->right;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
//删除结点的右节点为空
else if (cur->right == nullptr)
{
//删除结点是根节点
if (cur == root)
{
root = cur->left;
}
else
{
if (cur == parent->left)
{
parent->left = cur->left;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
//删除结点的左右结点均不为空
else
{
//查找右子树的最左结点替代删除
Node* rightMinParent = cur;
Node* rightMin = cur->right;
//遍历寻找
while (rightMin->left)
{
rightMinParent = rightMin;
rightMin = rightMin->left;
}
swap(cur->key, rightMin->key);
if (rightMinParent->left == rightMin)
rightMinParent->left = rightMin->right;
else
rightMinParent->right = rightMin->right;
delete rightMin;
}
return true;
}
}
return false;
}
public:
//套一层(友元、套一层、get三种方式获取类内的数据)
void InOrder()
{
_InOrder(root);
cout << endl;
}
private:
//循环遍历
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->left);
cout << root->key<< " ";
_InOrder(root->right);
}
private:
Node* root = nullptr;
};
void test()
{
int a[] = { 8,3,1,10,6,4,7,14,13 };
BSTree<int> t1;
//循环插入
for (auto e : a)
{
t1.Insert(e);
}
//中序遍历
t1.InOrder();
//删除结点
t1.erase(8);
//中序遍历
t1.InOrder();
}

- 时间复杂度:O(n)或 O(logn)
- O(n)

- O(logn)

二叉搜索树的实际应用
K和KV模型
K模型:只有key作为关键码,结构中只需存储key即可,key就是要搜索的值(以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误)
KV模型:每一个关键码key都有与之对应的值value,即<key,value>键值对(英汉词典中的中英文之间的对应关系<word,chinese>,通过中文可以快速找到对应的中文,统计单词的出现次数,统计成功后,给定某一个单词就能快速找到其出现的次数<word,count>)
查找的方式:
- 二分查找
- 二叉树搜索查找 -> AVL树和红黑树
- 哈希查找
- 跳表查找
- 多叉搜索树查找:B树系列
改造二叉搜索树为为KV模型
//KV模型
namespace key_value
{
template<class K,class V>
struct BSTreeNode
{
BSTreeNode<K,V>* left;
BSTreeNode<K,V>* right;
K key;
V _value;
BSTreeNode(const K& key,const V& value)
:left(nullptr)
,right(nullptr)
,key(key)
,_value(value)
{}
};
template<class K,class V>
class BSTree
{
typedef BSTreeNode<K,V> Node;
public:
bool Insert(const K& key,const V& value)
{
if (root == nullptr)
{
root = new Node(key,value);
return true;
}
Node* parent = nullptr;
Node* cur = root;
//遍历寻找
while (cur)
{
if (cur->key < key)//当前结点的值小于插入结点的值,就进入右子树判断
{
parent = cur;//走之前保留之前的信息,便于找到时向前一个结点尾插
cur = cur->right;
}
else if (cur->key > key)//当前结点的值大于插入结点的值,就进入左子树判断
{
parent = cur;
cur = cur->left;
}
else//相同时
{
return false;
}
}
//插入新节点
cur = new Node(key,value);
if (parent->key < key)
{
parent->right = cur;
}
else
{
parent->left = cur;
}
return true;//成功插入返回true
}
Node* Find(const K& key)
{
Node* cur = root;
while (cur)
{
if (cur->key < key)
{
cur = cur->right;
}
else if (cur->key > key)
{
cur = cur->left;
}
else
{
return cur;
}
}
return cur;
}
bool erase(const K& key)
{
Node* parent = nullptr;
Node* cur = root;
while (cur)
{
if (cur->key < key)
{
cur = cur->right;
}
else if (cur->key > key)
{
cur = cur->left;
}
//遍历寻找到要删除的值
else
{
//删除结点的左节点为空
if (cur->left == nullptr)
{
//删除结点是根节点
if (cur == root)
{
root = cur->right;
}
else
{
if (cur == parent->left)
{
parent->left = cur->right;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
//删除结点的右节点为空
else if (cur->right == nullptr)
{
//删除结点是根节点
if (cur == root)
{
root = cur->left;
}
else
{
if (cur == parent->left)
{
parent->left = cur->left;
}
else
{
parent->right = cur->left;
}
}
delete cur;
}
//删除结点的左右结点均不为空
else
{
//查找右子树的最左结点替代删除
Node* rightMinParent = cur;
Node* rightMin = cur->right;
//遍历寻找
while (rightMin->left)
{
rightMinParent = rightMin;
rightMin = rightMin->left;
}
swap(cur->key, rightMin->key);
if (rightMinParent->left == rightMin)
rightMinParent->left = rightMin->right;
else
rightMinParent->right = rightMin->right;
delete rightMin;
}
return true;
}
}
return false;
}
public:
//套一层(友元、套一层、get三种方式获取类内的数据)
void InOrder()
{
_InOrder(root);
cout << endl;
}
private:
//循环遍历
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
_InOrder(root->left);
cout << root->key << ":" <<root->_value<<endl;
_InOrder(root->right);
}
private:
Node* root = nullptr;
};
void test()
{
BSTree<string, string> dict;
dict.Insert("string","字符串");
dict.Insert("left", "左边");
dict.Insert("insert", "插入");
string str;
while (cin >> str)
{
BSTreeNode<string, string>* ret = dict.Find(str);//Find函数的返回值变为了结点的指针
if (ret)
{
cout << ret->_value << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
}
void test1()
{
//统计次数
string arr[] = { "苹果","西瓜","香蕉","西瓜","香蕉" ,"西瓜","香蕉" ,"西瓜","草莓" };
BSTree<string, int> countTree;
for (const auto& str : arr)
{
auto ret = countTree.Find(str);
if (ret == nullptr)
{
countTree.Insert(str, 1);
}
else
{
ret->_value++;
}
}
countTree.InOrder();
}
}

~over~


![[Rust开发]在Rust中使用geos的空间索引编码实例](https://img-blog.csdnimg.cn/img_convert/dd69614c137cedd7ebf831ae232263e8.png)